14 мая состоялся очередной семинар «Современные проблемы в машинном обучении и анализе данных», организованный на базе Института прикладной математики и механики и Института экономических исследований города Донецка сообществом DonbassDataScience. Максимова Александра Юреьевна сделала доклад на тему «Автоматическое дифференцирование».
Семинар уже второй раз проходил в режиме online, что позволило расширить аудиторию и географию слушателей .
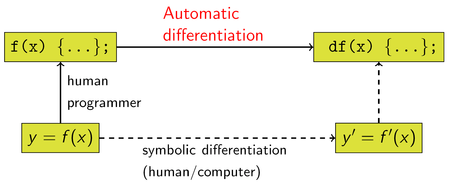
Автоматическое дифференцирование представляет собой набор методов для численной оценки производной функции, определенной компьютерной программой. Автоматическое дифференцирование использует тот факт, что каждая компьютерная программа, какой бы сложной она ни была, выполняет последовательность элементарных арифметических операций (сложение, вычитание, умножение, деление и т. Д.) и элементарных функций (exp, log, sin, cos и т. д.). Применяя последовательно правило дифференцирования сложной функции к этим операциям, производные произвольного порядка могут быть вычислены автоматически с заданной рабочей точностью.
Метод обратного распространения ошибки является специфической реализацией градиентного спуска в пространстве весов многослойных сетей прямого распространения. Основная идея этого метода заключается в эффективном вычислении частных производных функции сети по всем элементам настраиваемого вектора весов для данного входного вектора . Именно в этом заключается вычислительная мощь алгоритма обратного распространения. А автоматическое дифференцирование позволяет вычислять частные производные для глубоких нейронный сетей.
Целевая функция задачи оптимизации функции, которая описывает нейронную сеть, это сложная композиция других функций. При этом мы с легкостью можем вычислить значение функции в определенной точке признакового пространства, сделав прямой проход по сети. Автоматическое дифференцирование позволяет с легкостью вычислить производную этой функции в определенной точке.
В докладе автоматическое дифференцирование проиллюстрировано с помощью вычислительных графов.
Во второй части доклада показан пример класса Deriviative на Python, с помощью которого можно вычислить как значение скалярной функции в точке, так и ее производную в этой точке. Скачать файл можно по ссылке.
Второй пример иллюстрирует работу простого классификатора, написанного в Python с использованием библиотеки PyTorch. Скачать файл можно по ссылке.
Видео доклада:
Слайды к докладу можно скачать по ссылке.
Вопросы и обсуждение.
Вопрос 1. При обсуждении теоремы об универсальной аппроксимации возник вопрос, может ли функция φ быть линейной.
Теорема об универсальной аппроксимации говорит о том, что если у нас есть некоторая непрерывная функция f(x), то можно построить такую функцию F(x), которая по сути является двухслойной полносвязной сетью, то есть у нее N линейных моделей, от которых берется некоторая нелинейная (неконстантная, ограниченая, монотонно-возрастающая непрерывная) функция φ и строится линейная комбинация этих моделей с коэффициентами vi. Оказывается, что для любой непрерывной функции можно выбрать N (иногда это огромное число), что функция F(x) будет хорошо аппроксимировать f(x).Так как область определения φ не ограничена, линейная функция не подходит под определение ограниченная, а значит φ не может быть линейной.
В формулировке Цыбенко 1989 года функция φ сигмоидальная (также не линейная).
Cybenko, G. V. Approximation by Superpositions of a Sigmoidal function // Mathematics of Control Signals and Systems. — 1989. — Т. 2, № 4. — С. 303—314.
Очень интересной оказалась статья А.Н. Горбаня Обобщенная аппроксимационная теорема и вычислительные возможности нейронных сетей, в которой приводится доказательство утверждения об универсальных аппроксимационных свойствах любой нелинейности: с помощью линейных операций и каскадного соединения можно из произвольных нелинейных элементов получить любой требуемый результат с любой наперед заданной точностью.
Итак подведем итог, НЕЛИНЕЙНОСТЬ φ обязательна.
Вопрос 2. Как поступать, если функция перестает быть дифференцируемой, например является склейкой функций.
Ответ на этот вопрос из книги С. Николеко, А.Кадурин, Е.Архангельская Глубокое обучение. Погружение в мир нейронных сетей. Глава 2.
«Понятно, что формально говоря, применение градиентного спуска возможно только на дифференцируемых функциях, где производная будет известная в любой точке. Но в жизни, конечно, иногда попадаются и недифференцируемые функции, а иногда — функции с тривиальными производными. Например, в обучении с подкреплением известно только текущее значение функции ценности. А в обучении ранжированию, когда мы хотим получить на выходе некое упорядочивание объектов по какому-то критерию, например в выдаче поисковика или рекомендательной системы, оказывается, что градиент функции ошибки почти всегда равен нулю!
Действительно, представьте себе поисковую выдачу, упорядоченную по релевантности документа запросу. Релевантность — это и есть функция, которую мы приближаем моделью (например нейронной сетью). Но в случае обучения ранжированию небольшие изменения в весах приводят в небольших изменениях релевантности каждого документа и в результате сравнительный порядок почти никогда не меняется при малых изменениях весов. Но целевая функция зависит только от порядка. Получается, что функция ошибки кусочно-постоянна, состоит из большого числа маленьких горизонтальных «островков», и градиент от нее абсолютно бесполезен: он либо равен нули, либо не существует.
Что же делать в таких случаях? Оказывается, что градиентный спуск — это настолько всеобъемлющий метод, что альтернатив ему совсем мало. Методы оптимизации в основном занимаются тем, что ускоряют градиентный спуск, разрабатывают разные его варианты, добавляют ограничения, но принципиально других методов почти нет. Поэтому когда градиентный спуск неприменим, решение состоит в том, чтобы все таки именно его и применить.
В зависимости от того, в чем состоит сложность, можно воспользоваться такими приемами:
- Если производная есть, но вычислить ее не получается, а можно считать только значение функций в разных точках, то производную можно подсчитать приближенно.
- Если производной совсем нет, то приближать скорее всего придется саму функцию, которую мы пытаемся оптимизировать. Можно попробовать выбрать достаточно «хорошо ведущую себя» функцию, которая похожа на ту, что мы хотим оптимизировать.
- Если производная тривиальна, как в случае обучения ранжированию, то подлежащую оптимизацию функцию тоже приходится модифицировать. При обучении ранжированию, например, мы будем оптимизировать не саму функцию качества, зависящую только от расположения элементов в списке, а некую специальную функцию ошибки, которая будет тем больше, чем «более ошибочно» окажется вычисление релевантности.»
> Так как область определения φ не ограничена,
Вот этого требования как раз не было указано в условии теоремы на слайде. А похоже что именно это и важно. Статья Цыбенко вообще начинается с того, что предел на -inf у фукнции должен быть равен 0, а на +inf — 1.
Хотя понятно, что какие бы там ни были пределы (лишь бы конечные) — их можно масштабированием свести к [0,1].
Кстати, с учетом требования о монотонности это просто обозначает, что функцию sigma можно рассматривать как функцию распределения некоторой случайной величины.
> Ответ на этот вопрос из книги С. Николеко, А.Кадурин, Е.Архангельская Глубокое обучение. Погружение в мир нейронных сетей. Глава 2.
Достаточно интересно.
Но такое ощущение, что непосредственно автоматическое дифференцирование мы в таких случаях применять не можем. Когда у нас есть аналитический вид фукнции, выраженный как композиция элементарных функций, от которых мы умеем считать производные — все будет замечательно. Как только, у нас появляются склейки, табличное представление или не дай бог какие-нибудь специальные функции (типа Гамма-функции или эллиптических функций, которые вычисляются как несобственные интегралы от чего-нибудь и не выражаются конечным образом через элементарные) — об автоматическом дифференцировании, судя по всему, речи быть не может.